How browser works
lang_of_article_differ
want_proper_trans
This comprehensive primer on the internal operations of WebKit and Gecko is the result of much research done by Israeli developer Tali Garsiel. Over a few years, she reviewed all the published data about browser internals (see Resources) and spent a lot of time reading web browser source code
Introduction
Web browsers are probably the most widely used software. In this book I will explain how they work behind the scenes. We will see what happens when you type 'google.com' in the address bar until you see the Google page on the browser screen.
Contents
- Introduction. The browsers we will talk about
- The rendering engine. Rendering engines
- The main flow
- Main flow examples
- Parsing and DOM tree construction. Parsing - general. Grammars
- Parser - Lexer combination
- Translation
- Parsing example
- Formal definitions for vocabulary and syntax
- Types of parsers
- Generating parsers automatically
- HTML Parser. The HTML grammar definition
- Not a context free grammar
- HTML DTD
- DOM
- The parsing algorithm
- The tokenization algorithm
- Tree construction algorithm
- Actions when the parsing is finished
- Browsers error tolerance
- CSS parsing. Webkit CSS parser
- Parsing scripts
- The order of processing scripts and style sheets. Scripts
- Speculative parsing
- Style sheets
- Render tree construction. The render tree relation to the DOM tree
- Style Computation. Sharing style data
- Layout. Dirty bit system
- Painting. Global and Incremental
- Parsing and DOM tree construction. Parsing - general. Grammars
- Dynamic changes
- Resources
The browsers we will talk about
There are five major browsers used today - Internet Explorer, Firefox, Safari, Chrome and Opera.
I will give examples from the open source browsers - Firefox,Chrome and Safari, which is partly open source.
According to the W3C browser statistics, currently(October 2009), the usage share of Firefox, Safari and Chrome together is nearly 60%.
So nowdays open source browsers are a substantial part of the browser business.
The browser's main functionality
The browser main functionality is to present the web resource you choose, by requesting it from the server and displaying it on the browser window. The resource format is usually HTML but also PDF, image and more. The location of the resource is specified by the user using a URI (Uniform resource Identifier). More on that in the network chapter.
The way the browser interprets and displays HTML files is specified in the HTML and CSS specifications. These specifications are maintained by the W3C (World Wide Web Consortium) organization, which is the standards organization for the web.
The current version of HTML is 4 (http://www.w3.org/TR/html401/). Version 5 is in progress. The current CSS version is 2 (http://www.w3.org/TR/CSS2/) and version 3 is in progress.
For years browsers conformed to only a part of the specifications and developed their own extensions. That caused serious compatibility issues for web authors. Today most of the browsers more or less conform to the specifications.
Browsers' user interface have a lot in common with each other. Among the common user interface elements are:
- Address bar for inserting the URI
- Back and forward buttons
- Bookmarking options
- A refresh and stop buttons for refreshing and stopping the loading of current documents
- Home button that gets you to your home page
Strangely enough, the browser's user interface is not specified in any formal specification, it is just good practices shaped over years of experience and by browsers imitating each other. The HTML5 specification doesn't define UI elements a browser must have, but lists some common elements. Among those are the address bar, status bar and tool bar. There are, of course, features unique to a specific browser like Firefox downloads manager.
More on that in the user interface chapter.
The browser's high level structure
The browser's main components are (1.1):
- The user interface - this includes the address bar, back/forward button, bookmarking menu etc. Every part of the browser display except the main window where you see the requested page.
- The browser engine - the interface for querying and manipulating the rendering engine.
- The rendering engine - responsible for displaying the requested content. For example if the requested content is HTML, it is responsible for parsing the HTML and CSS and displaying the parsed content on the screen.
- Networking - used for network calls, like HTTP requests. It has platform independent interface and underneath implementations for each platform.
- UI backend - used for drawing basic widgets like combo boxes and windows. It exposes a generic interface that is not platform specific. Underneath it uses the operating system user interface methods.
- JavaScript interpreter. Used to parse and execute the JavaScript code.
- Data storage. This is a persistence layer. The browser needs to save all sorts of data on the hard disk, for examples, cookies. The new HTML specification (HTML5) defines 'web database' which is a complete (although light) database in the browser.
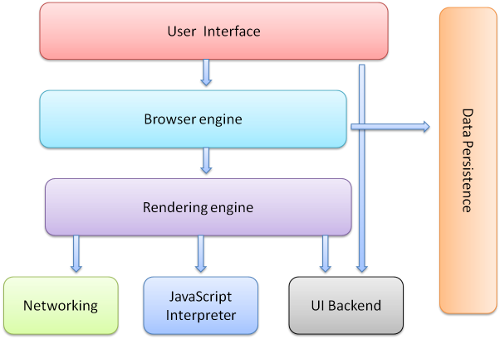 Figure 1: Browser main components.
Figure 1: Browser main components.It is important to note that Chrome, unlike most browsers, holds multiple instances of the rendering engine - one for each tab,. Each tab is a separate process.
I will devote a chapter for each of these components.
Communication between the components
Both Firefox and Chrome developed a special communication infrastructures.
They will be discussed in a special chapter.
The rendering engine
The responsibility of the rendering engine is well... Rendering, that is display of the requested contents on the browser screen.
By default the rendering engine can display HTML and XML documents and images. It can display other types through a plug-in (a browser extension). An example is displaying PDF using a PDF viewer plug-in. We will talk about plug-ins and extensions in a special chapter. In this chapter we will focus on the main use case - displaying HTML and images that are formatted using CSS.
Rendering engines
Our reference browsers - Firefox, Chrome and Safari are built upon two rendering engines. Firefox uses Gecko - a "home made" Mozilla rendering engine. Both Safari and Chrome use Webkit.
Webkit is an open source rendering engine which started as an engine for the Linux platform and was modified by Apple to support Mac and Windows. See http://webkit.org/ for more details.
The main flow
The rendering engine will start getting the contents of the requested document from the networking layer. This will usually be done in 8K chunks.
After that this is the basic flow of the rendering engine:
 Figure 2:Rendering engine basic flow.
Figure 2:Rendering engine basic flow.
The rendering engine will start parsing the HTML document and turn the tags to DOM nodes in a tree called the "content tree". It will parse the style data, both in external CSS files and in style elements. The styling information together with visual instructions in the HTML will be used to create another tree - the render tree.
The render tree contains rectangles with visual attributes like color and dimensions. The rectangles are in the right order to be displayed on the screen.
After the construction of the render tree it goes through a "layout" process. This means giving each node the exact coordinates where it should appear on the screen. The next stage is painting - the render tree will be traversed and each node will be painted using the UI backend layer.
It's important to understand that this is a gradual process. For better user experience, the rendering engine will try to display contents on the screen as soon as possible. It will not wait until all HTML is parsed before starting to build and layout the render tree. Parts of the content will be parsed and displayed, while the process continues with the rest of the contents that keeps coming from the network.
Main flow examples
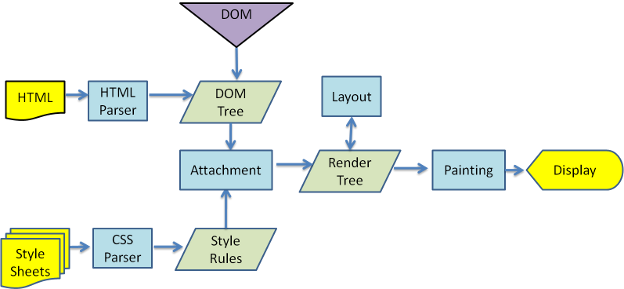 Figure 3: Webkit main flow
Figure 3: Webkit main flow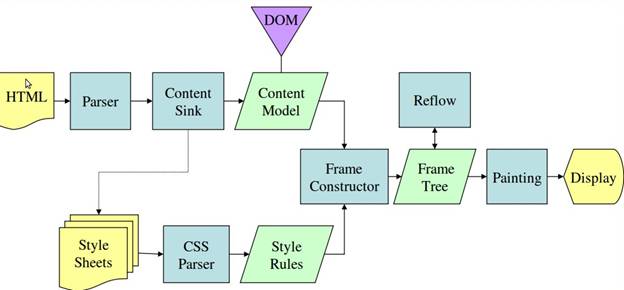
Figure 4: Mozilla's Gecko rendering engine main flow(3.6)
From figures 3 and 4 you can see that although Webkit and Gecko use slightly different terminology, the flow is basically the same.
Gecko calls the tree of visually formatted elements - Frame tree. Each element is a frame. Webkit uses the term "Render Tree" and it consists of "Render Objects". Webkit uses the term "layout" for the placing of elements, while Gecko calls it "Reflow". "Attachment" is Webkit's term for connecting DOM nodes and visual information to create the render tree. A minor non semantic difference is that Gecko has an extra layer between the HTML and the DOM tree. It is called the "content sink" and is a factory for making DOM elements. We will talk about each part of the flow:
Parsing - general
Since parsing is a very significant process within the rendering engine, we will go into it a little more deeply. Let's begin with a little introduction about parsing.
Parsing a document means translating it to some structure that makes sense - something the code can understand and use. The result of parsing is usually a tree of nodes that represent the structure of the document. It is called a parse tree or a syntax tree.
Example - parsing the expression "2 + 3 - 1" could return this tree:
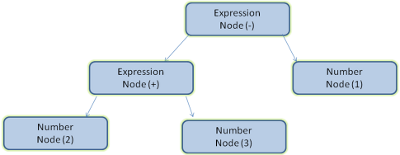 Figure 5: mathematical expression tree node
Figure 5: mathematical expression tree nodeGrammars
Parsing is based on the syntax rules the document obeys - the language or format it was written in. Every format you can parse must have deterministic grammar consisting of vocabulary and syntax rules. It is called a context free grammar. Human languages are not such languages and therefore cannot be parsed with conventional parsing techniques.
Parser - Lexer combination
Parsing can be separated into two sub processes - lexical analysis and syntax analysis.
Lexical analysis is the process of breaking the input into tokens. Tokens are the language vocabulary - the collection of valid building blocks. In human language it will consist of all the words that appear in the dictionary for that language.
Syntax analysis is the applying of the language syntax rules.
Parsers usually divide the work between two components - the lexer(sometimes called tokenizer) that is responsible for breaking the input into valid tokens, and the parser that is responsible for constructing the parse tree by analyzing the document structure according to the language syntax rules. The lexer knows how to strip irrelevant characters like white spaces and line breaks.
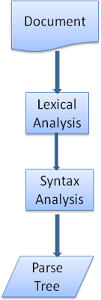 Figure 6: from source document to parse trees
Figure 6: from source document to parse treesThe parsing process is iterative. The parser will usually ask the lexer for a new token and try to match the token with one of the syntax rules. If a rule is matched, a node corresponding to the token will be added to the parse tree and the parser will ask for another token.
If no rule matches, the parser will store the token internally, and keep asking for tokens until a rule matching all the internally stored tokens is found. If no rule is found then the parser will raise an exception. This means the document was not valid and contained syntax errors.
Translation
Many times the parse tree is not the final product. Parsing is often used in translation - transforming the input document to another format. An example is compilation. The compiler that compiles a source code into machine code first parses it into a parse tree and then translates the tree into a machine code document.
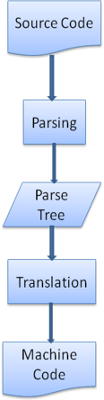 Figure 7: compilation flow
Figure 7: compilation flowParsing example
In figure 5 we built a parse tree from a mathematical expression. Let's try to define a simple mathematical language and see the parse process.
Vocabulary: Our language can include integers, plus signs and minus signs.
Syntax:
-
The language syntax building blocks are expressions, terms and operations.
-
Our language can include any number of expressions.
-
A expression is defined as a "term" followed by an "operation" followed by another term
-
An operation is a plus token or a minus token
-
A term is an integer token or an expression
Let's analyze the input "2 + 3 - 1".
The first substring that matches a rule is "2", according to rule #5 it is a term. The second match is "2 + 3" this matches the second rule - a term followed by an operation followed by another term. The next match will only be hit at the end of the input. "2 + 3 - 1" is an expression because we already know that ?2+3? is a term so we have a term followed by an operation followed by another term. "2 + + "will not match any rule and therefore is an invalid input.
Formal definitions for vocabulary and syntax
Vocabulary is usually expressed by regular expressions.
For example our language will be defined as:
INTEGER: 0|[1-9][0-9]*
PLUS: +
MINUS: -As you see, integers are defined by a regular expression.
Syntax is usually defined in a format called BNF. Our language will be defined as:
expression := term operation term
operation := PLUS | MINUS
term := INTEGER | expressionWe said that a language can be parsed by regular parsers if its grammar is a context frees grammar. An intuitive definition of a context free grammar is a grammar that can be entirely expressed in BNF. For a formal definition see http://en.wikipedia.org/wiki/Context-free_grammar
Types of parsers
There are two basic types of parsers - top down parsers and bottom up parsers. An intuitive explanation is that top down parsers see the high level structure of the syntax and try to match one of them. Bottom up parsers start with the input and gradually transform it into the syntax rules, starting from the low level rules until high level rules are met.
Let's see how the two types of parsers will parse our example:
Top down parser will start from the higher level rule - it will identify "2 + 3" as an expression. It will then identify "2 + 3 - 1" as an expression (the process of identifying the expression evolves matching the other rules, but the start point is the highest level rule).
The bottom up parser will scan the input until a rule is matched it will then replace the matching input with the rule. This will go on until the end of the input. The partly matched expression is placed on the parsers stack.
| Stack | Input |
|---|---|
| 2 + 3 - 1 | |
| term | + 3 - 1 |
| term operation | 3 - 1 |
| expression | - 1 |
| expression operation | 1 |
| expression |
Generating parsers automatically
There are tools that can generate a parser for you. They are called parser generators. You feed them with the grammar of your language - its vocabulary and syntax rules and they generate a working parser. Creating a parser requires a deep understanding of parsing and its not easy to create an optimized parser by hand, so parser generators can be very useful.
Webkit uses two well known parser generators - Flex for creating a lexer and Bison for creating a parser (you might run into them with the names Lex and Yacc). Flex input is a file containing regular expression definitions of the tokens. Bison's input is the language syntax rules in BNF format.
HTML Parser
The job of the HTML parser is to parse the HTML markup into a parse tree.
The HTML grammar definition
The vocabulary and syntax of HTML are defined in specifications created by the w3c organization. The current version is HTML4 and work on HTML5 is in progress.
Not a context free grammar
As we have seen in the parsing introduction, grammar syntax can be defined formally using formats like BNF.
Unfortunately all the conventional parser topics do not apply to HTML (I didn't bring them up just for fun - they will be used in parsing CSS and JavaScript). HTML cannot easily be defined by a context free grammar that parsers need.
There is a formal format for defining HTML - DTD (Document Type Definition) - but it is not a context free grammar.
This appears strange at first site - HTML is rather close to XML .There are lots of available XML parsers. There is an XML variation of HTML - XHTML - so what's the big difference?
The difference is that HTML approach is more "forgiving", it lets you omit certain tags which are added implicitly, sometimes omit the start or end of tags etc. On the whole it's a "soft" syntax, as opposed to XML's stiff and demanding syntax.
Apparently this seemingly small difference makes a world of a difference. On one hand this is the main reason why HTML is so popular - it forgives your mistakes and makes life easy for the web author. On the other hand, it makes it difficult to write a format grammar. So to summarize - HTML cannot be parsed easily, not by conventional parsers since its grammar is not a context free grammar, and not by XML parsers.
HTML DTD
HTML definition is in a DTD format. This format is used to define languages of the SGML family. The format contains definitions for all allowed elements, their attributes and hierarchy. As we saw earlier, the HTML DTD doesn't form a context free grammar.
There are a few variations of the DTD. The strict mode conforms solely to the specifications but other modes contain support for markup used by browsers in the past. The purpose is backwards compatibility with older content. The current strict DTD is here: http://www.w3.org/TR/html4/strict.dtd
DOM
The output tree - the parse tree is a tree of DOM element and attribute nodes. DOM is short for Document Object Model. It is the object presentation of the HTML document and the interface of HTML elements to the outside world like JavaScript.
The root of the tree is the "Document" object.
The DOM has an almost one to one relation to the markup. Example, this markup:
<html>
<body>
<p>
Hello World
</p>
<div> <img src="example.png"/></div>
</body>
</html>Would be translated to the following DOM tree:
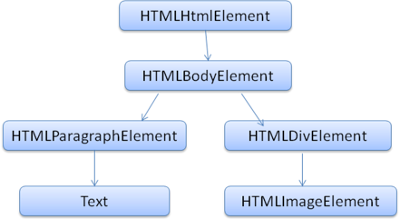 Figure 8: DOM tree of the example markup
Figure 8: DOM tree of the example markup
Like HTML, DOM is specified by the w3c organization. See http://www.w3.org/DOM/DOMTR. It is a generic specification for manipulating documents. A specific module describes HTML specific elements. The HTML definitions can be found here: http://www.w3.org/TR/2003/REC-DOM-Level-2-HTML-20030109/idl-definitions.html.
When I say the tree contains DOM nodes, I mean the tree is constructed of elements that implement one of the DOM interfaces. Browsers use concrete implementations that have other attributes used by the browser internally.
The parsing algorithm
As we saw in the previous sections, HTML cannot be parsed using the regular top down or bottom up parsers.
The reasons are:
- The forgiving nature of the language.
- The fact that browsers have traditional error tolerance to support well known cases of invalid HTML.
- The parsing process in reentrant. Usually the source doesn't change during parsing, but in HTML, script tags containing "document.write" can add extra tokens, so the parsing process actually modifies the input.
Unable to use the regular parsing techniques, browsers create custom parsers for parsing HTML.
The parsing algorithm is described in details by the HTML5 specification. The algorithm consists of two stages - tokenization and tree construction.
Tokenization is the lexical analysis, parsing the input into tokens. Among HTML tokens are start tags, end tags, attribute names and attribute values.
The tokenizer recognizes the token, gives it to the tree constructor and consumes the next character for recognizing the next token and so on until the end of the input.
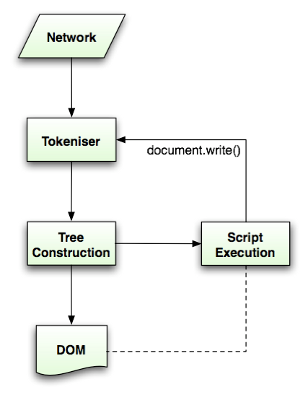 Figure 6: HTML parsing flow (taken from HTML5 spec)
Figure 6: HTML parsing flow (taken from HTML5 spec)The tokenization algorithm
The algorithm's output is an HTML token. The algorithm is expressed as a state machine. Each state consumes one or more characters of the input stream and updates the next state according to those characters. The decision is influenced by the current tokenization state and by the tree construction state. This means the same consumed character will yield different results for the correct next state, depending on the current state. The algorithm is too complex to bring fully, so let's see a simple example that will help us understand the principal.
Basic example - tokenizing the following HTML:
<html>
<body>
Hello world
</body>
</html>The initial state is the "Data state". When the "<" character is encountered, the state is changed to "Tag open state". Consuming an "a-z" character causes creation of a "Start tag token", the state is change to "Tag name state". We stay in this state until the ">" character is consumed. Each character is appended to the new token name. In our case the created token is an "html" token.
When the ">" tag is reached, the current token is emitted and the state changes back to the "Data state". The "
" tag will be treated by the same steps. So far the "html" and "body" tags were emitted. We are now back at the "Data state". Consuming the "H" character of "Hello world" will cause creation and emitting of a character token, this goes on until the "<" of "" is reached. We will emit a character token for each character of "Hello world".We are now back at the "Tag open state". Consuming the next input "/" will cause creation of an "end tag token" and a move to the "Tag name state". Again we stay in this state until we reach ">".Then the new tag token will be emitted and we go back to the "Data state". The "